Objectif
Analyser les dépendances entre deux variables "catégorielles"
(Par exemple parfum "pistache", "fraise" ou "citron")
...
Données
En lignes : $n$ "individus"
En colonnes : $m$ "variables" qualitatives
| Couleur | Marque | |
|---|---|---|
| Voiture 1 | rouge | Opel |
| Voiture 2 | bleue | Citroën |
| Voiture 3 | jaune | Toyota |
| ... | ... | ... |
Valeurs possibles = "modalités"
Transformation
On compte les associations :
marque $\in$ { Opel, Citroën, Toyota }
couleur $\in$ { rouge, bleue, jaune }
Exemple : marque vs. couleur
| Opel | Citroën | Toyota | |
|---|---|---|---|
| rouge | 13 | 5 | 7 |
| bleue | 3 | 15 | 6 |
| jaune | 7 | 17 | 20 |
Écart à l'indépendance
Idée = mesurer l'"écart à l'indépendance"
Indépendance (apparente) = effectifs totaux par lignes répartis selon les pourcentages d'effectifs totaux par colonnes.
| Opel | Citroën | Toyota | |
|---|---|---|---|
| rouge | 6 | 10 | 9 |
| bleue | 6 | 9.5 | 8.5 |
| jaune | 11 | 17.5 | 15.5 |
Détails du calcul
Les effectifs théoriques (en cas d'indépendance) se calculent en multipliant la marge colonne par la marge ligne : on obtient une matrice, qui faut ensuite diviser par le nombre d'individus (somme de tous les éléments). Exemple :
library(FactoMineR) ; data(children)
data <- children[1:14,1:5]
marge_colonne <- rowSums(data)
marge_ligne <- colSums(data)
effectifs_theoriques <-
as.matrix(marge_colonne) %*% marge_ligne / sum(data)Comprendre le calcul
L'idée est de faire en sorte qu'étant donné une modalité M ligne ou colonne, les probabilités associées ne dépendent que des effectifs totaux par colonnes, et soient donc indépendantes de M.
Par exemple si data =$\begin{pmatrix} 35 & 3\\ 33 & 65\end{pmatrix}$, les deux colonnes sont de même poids et il n'y a pas indépendance.
Tous les calculs peuvent se faire en inversant lignes et colonnes (mêmes résultats, à une transposition près...)
Exercice
Mettez le jeu de données suivant sous forme de table (comptant les associations). Calculez ensuite le tableau des effectifs théoriques.
"Faut-il atterrir en pilotage automatique ?"
- auto/noauto :
oui ou non. - head/tail :
direction du vent
(...)
| noauto | tail |
| auto | head |
| auto | head |
| auto | tail |
| auto | tail |
| noauto | head |
| auto | tail |
Quantification de l'écart à l'indépendance
$$\chi^2 = \sum_{i=1}^{n} \frac{(o_i - t_i)^2}{t_i}$$
$o_i$ : premier tableau, observé.
$t_i$ : second tableau, théorique.
= Test du $\chi^2$. Dépendance $\Leftrightarrow$ $\chi^2 \geq$ seuil.
# En R :
chi2 = sum( (effectifs_theoriques - data)^2 / effectifs_theoriques )Algorithme de représentation
- ACP [*] sur les lignes normalisées (somme = 1)
- ACP [*] sur les colonne normalisées (somme = 1)
- Représentation simultanée (lignes + colonnes)
[*] distance euclidienne pondérée :
plus de poids sur les modalités rares.
Inertie totale = $\phi = \chi^2 / n$
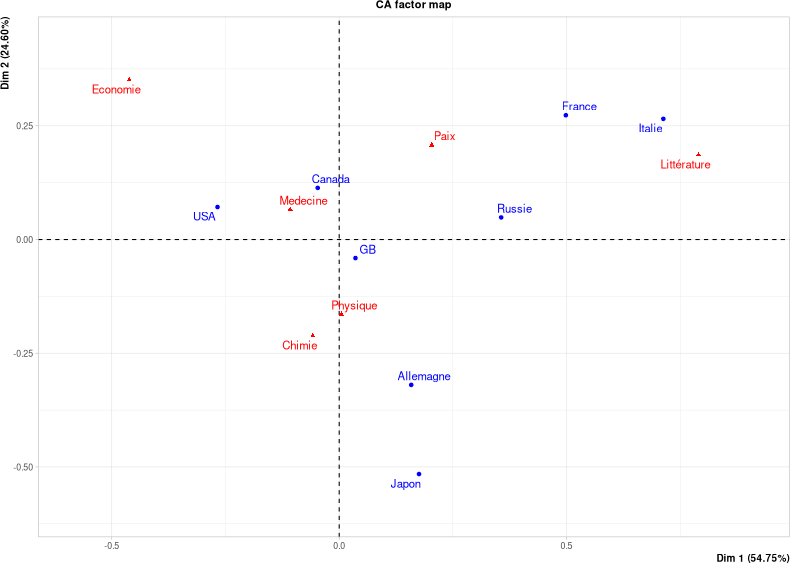
Exemple : prix Nobel (discipline vs. pays)
| Chimie | Economie | Littérature | Medecine | Paix | Physique | |
|---|---|---|---|---|---|---|
| Allemagne | 24 | 1 | 8 | 18 | 5 | 24 |
| Canada | 4 | 3 | 2 | 4 | 1 | 4 |
| France | 8 | 3 | 11 | 12 | 10 | 9 |
| GB | 23 | 6 | 7 | 26 | 11 | 20 |
| Italie | 1 | 1 | 6 | 5 | 1 | 5 |
| Japon | 6 | 0 | 2 | 3 | 1 | 11 |
| Russie | 4 | 3 | 5 | 2 | 3 | 10 |
| USA | 51 | 43 | 8 | 70 | 19 | 66 |
Lien entre pays et catégorie de prix ?
Avec R
# Lecture / https://www.kaggle.com/nobelfoundation/nobel-laureates
data = read.csv("Prix_Nobel.csv")
# Transformation
t = table(data[,c(2,11)])
# Chargement de FactoMineR
library(FactoMineR)
# AFC
res.ca = CA(t)Sélection des colonnes 2 et 11 (catégorie / pays)
Résultat
Comment interpréter ?
Attention :
points bleus et rouges à différentes échelles.
$\Rightarrow$ distances non interprétables ; mais directions oui.
Attention : axes à échelles différentes.
- Modalités rares / atypiques plus éloignées du centre.
- Modalités associées si "du même côté".
Interprétation
- Italie obtient proportionnellement plus de prix en littérature (vs. profil moyen / autres pays).
- Japon et Allemagne : plutôt physique/chimie.
- USA : + économie (comparée au autres).
- GB très proche du profil moyen (au centre).
- Axe 1 (x) oppose sciences et littérature.
- Axe 2 (y) oppose physique/chimie et économie.
Retour à l'exemple "voitures"
v = matrix(c(13,3,7, 5,15,17, 7,6,20), nrow=3)
res.ca = CA(v)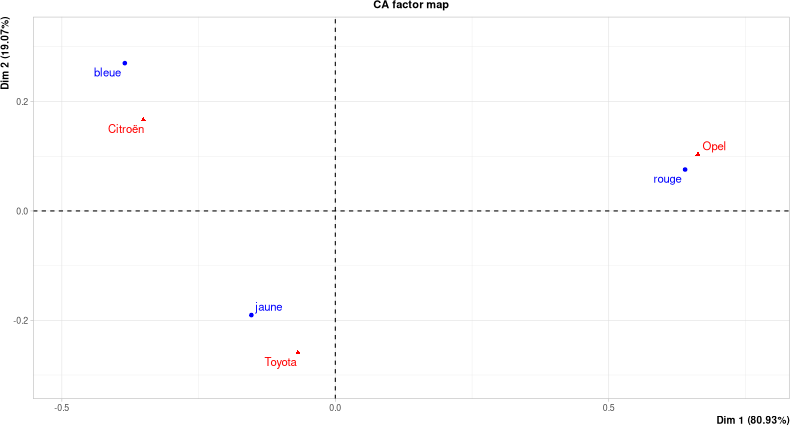
v = matrix(c(13,3,3, 5,15,8, 7,6,10), nrow=3)
res.ca = CA(v)
Ligne 3 divisée par 2 : devient plus rare, mais pas de changements dans les associations.
v = matrix(c(13,3,7, 5,15,17, 7,18,20), nrow=3)
res.ca = CA(v)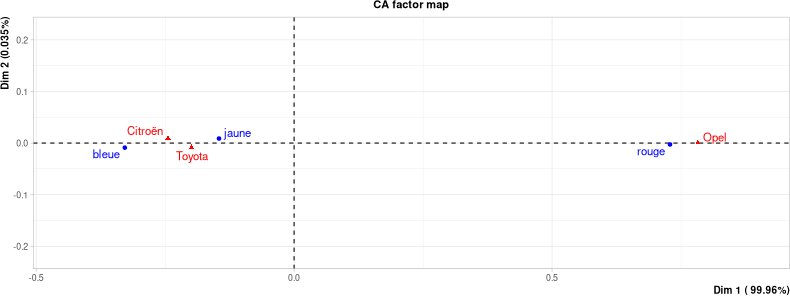
Colonnes (et lignes) 2 et 3 très similaires :
Situation proche de l'indépendance (côté gauche).
Équivalence distributionnelle
Les résultats ne changent pas si plusieurs lignes / colonnes proportionnelles sont regroupées.
("Exercice" : le vérifier !)
Intuition : les poids sont regroupés en un point sans changer dans l'autre dimension.
Exercice 0
Lancez R, installez FactoMineR, puis chargez table_Nobel.csv
(Données déjà transformées).
Effectuez une AFC, puis modifiez un peu les données en observant les effets. Essayez de les expliquer.
Exercice 1
Récupérez le jeu de données "musées"
Effectuez une AFC (sur les colonnes appropriées) et commentez le résultat.
Exercice 2
Récupérez le jeu de données "peintures"
Effectuez quelques AFC et analysez les résultats.
Suggestion de "corrigé"
Pour aller plus loin (hors programme)
Allez voir le cours de François Husson sur l'ACM (Analyse des Correspondances Multiples). Cette méthode permet de prendre en compte simultanément plusieurs variables qualitatives, et est donc utile en particulier pour analyser des résultats de sondages.